
Plant Shutdowns are necessary when maintenance work is required and the plant cannot be running while that work is being performed. Total Plant Shutdowns can be very large and expensive events and, in a downturn such as is currently being experienced in the mining, mineral processing, oil & gas sectors are often the focus of cost reduction opportunities. At face value, it can appear that there is significant money to be saved by increasing the time interval between shutdowns. The rationale is generally this:
- Shutdowns are expensive
- If we increase the interval between shutdowns, then we will have fewer shutdowns per year
- This will reduce the direct cost shutdowns per year
- It will also reduce the planned downtime per year, giving us the opportunity to produce more product (and make a profit on that additional production)
- Yes, there is a risk that stretching the interval between shutdowns will increase unplanned downtime between shutdowns, but we don’t expect that this will be significant – and in any case, how will we know what the impact will be unless we try?
Let’s examine this rationale by discussing the five key questions you should ask before you extend the interval between shutdowns.
What is your failure data telling you?
Before you make any decisions, it is wise to look at the failures that are occurring between your major shutdowns. What is causing them? When are these failures typically occurring?
For example, for a mining client we recently did just that for one of their processing plants. The resulting analysis showed:
- Many unplanned failures which caused plant shutdowns occurred shortly after (within 1 week) of a major planned shutdown.
- Some unplanned shutdowns (which were mostly related to fatigue on a particular major component) occurred shortly before (within 2 weeks of) the next planned shutdown.
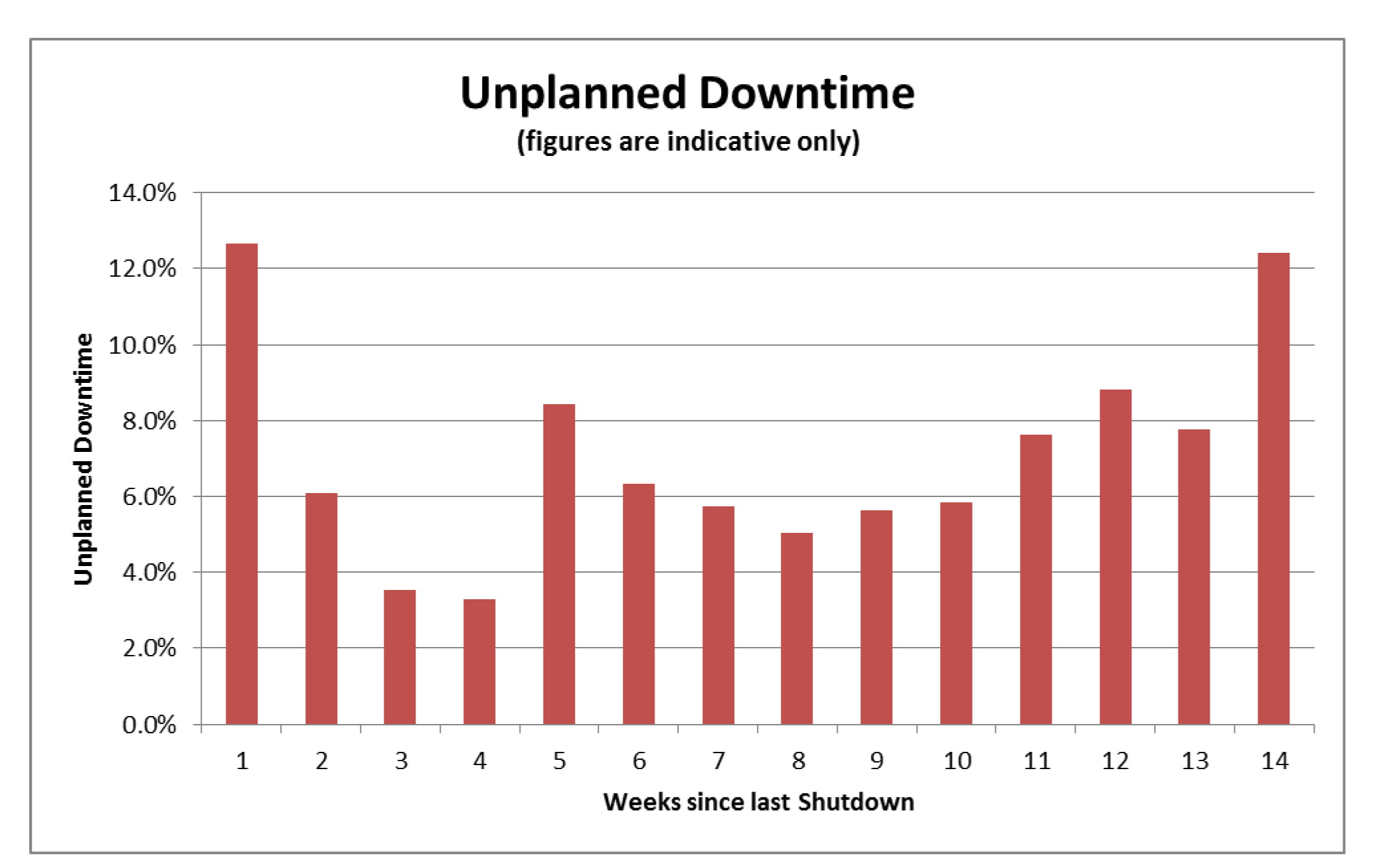
This indicated that, in this case, there was one particular component that was struggling to operate reliably until the next planned shutdown. Extending the shutdown frequency without addressing this issue would only be likely to cause even more unplanned downtime. Performing this analysis allowed the client to focus on addressing that particular issue, and also assisted him to quantify the impact of those premature failures and build the business case for some significant capital investment to resolve it.
However the existence of a number of early life failures shortly after a shutdown indicated another opportunity for improvement. Why were these occurring? What could be done to reduce or eliminate these? In this particular case it indicated a need to focus attention on:
- whether the right Preventive Maintenance tasks were being done on the shutdown
- whether work instructions and inspection sheets provided adequate detail to ensure that tasks could be done consistently and to the required quality standard
- whether the skills of the contractors being used on the shutdown were adequate
- whether the level of supervision of those contractors was adequate to ensure quality
- whether the work was adequately planned and all resources required to perform the planned work were available
- whether the quality of spare parts and materials being procured was adequate
The size of that prize was at least as great as the potential benefits of increasing shutdown frequency.
What is the main driver of business value?
Will you generate more cash for your business by reducing the direct costs of a shutdown, or by maximising total uptime? We discussed this issue in a previous article“What Happens When You Cut the Maintenance Budget?” There is a risk, when extending the interval between shutdowns, that although total planned downtime is reduced, the plant may become less reliable between shutdowns, resulting in an increase in unplanned downtime, which can create three sorts of problems. First, if unplanned downtime increases by more than the reduction in planned downtime, then total plant uptime will be reduced. Second, unplanned downtime (including associated production losses, freight, labour efficiency and so on) is usually more expensive than planned downtime. In either case, if this results in a loss of profit that is greater than the amount of money saved by reducing the direct costs of the shutdown, then there is a net loss to the organisation – not a gain. Third, it is now commonly recognised that performing unplanned maintenance work represents one of the greatest risks to health and safety in industrial workplaces. If the number of unplanned maintenance events increases as a result of the change in shutdown interval, then we are increasing those risks.
In our experience, in most asset-intensive industries where 24 hour/day operation is the norm, there is considerably more money to be made by maximising plant uptime than there is to be saved by reducing direct maintenance costs. In the ideal world, we aim to do both – maximise plant uptime and minimise costs. But if gains in one are offset by losses in the other, it is generally best to focus on a goal of maximising plant uptime.
Understanding the relationship between the two, and the comparative value to be gained from each – direct cost reduction and plant uptime maximisation – helps you to focus on a shutdown strategy that will deliver maximum value for your business.
Why are you shutting down?
The next question to ask is why you are shutting down. There are two things to consider here.
First, shutdown work should be exactly that, work on equipment that cannot be performed whilst equipment is operational. We suggest that you critically review the list of tasks performed on each shutdown. In the past, when we have done this for clients, we inevitably unearth routine tasks and minor maintenance included in the scope of shutdowns that can be performed either while the plant is running, or occasionally that can be performed during a partial (or modular) plant shutdown. Removing these tasks from the shutdown scope assists you to focus on those tasks that are the primary reason for shutting down.
Second, having done that, you should then identify the tasks that you do every shutdown. One or more of these will be the critical tasks that are driving your shutdown frequency. List these, because you should critically review these in the manner discussed below. In particular, you should pay special attention to those tasks that are preventing failures that, if they were to occur while the equipment was in service, the consequences would be greatest, because if you don’t get those right, then the outcomes could be career-limiting!. PM Optimisation is a great approach to use for performing this analysis.
How often do you really need to shutdown?
For each of the tasks that you do every shutdown, we recommend that you classify these tasks using the following four categories. All tasks should fit into one and only one of these categories.
- Fixed Interval Replacements or Overhauls – these are tasks where you are going to either replace or overhaul an equipment item or component at a pre-determined, fixed interval (which can be measured in days, tonnes, kilometres or whatever unit is applicable) regardless of its condition at the time.
- Condition Based Inspections – these are tasks where you are going to perform an inspection on an equipment item or component at a pre-determined fixed interval in order to determine whether the item or component is about to fail. Obviously, the inspection should be one that can only be performed with the plant offline.
- Failure Finding Tasks/Functional Tests – these are inspections or tests that you are going to perform (typically on protective devices and systems) at a pre-determined fixed interval in order to determine whether the item or component has already failed.
- Corrective Maintenance Tasks – these are repairs that arise based on the results of previous Condition Based Inspections of Failure Finding Tasks/Functional Tests. While the inspections or tests may have been able to be performed with the plant running, the repairs can only be performed with the plant shutdown.
There are two reasons for classifying the tasks into these categories:
- Reliability Centered Maintenance principles tells us that the drivers of task frequency (and therefore shutdown frequency) are different for each of these categories, and
- The options available for changing the frequencies of these tasks are different for each category.
For each of the task categories listed above, Reliability Centered Maintenance principles tell us that the driver of task frequency (and therefore shutdown frequency) is as follows:
| Task Category | Driver |
|---|---|
| Fixed interval replacements or overhauls | The useful “life” of the equipment item or component. |
| Condition based inspections | The PF Interval – the amount of warning that you get that the item is about to fail. |
| Failure finding tasks / functional tests | The reliability of the protective device, the reliability of the protected function and the level of risk that the organisation is prepared to tolerate that the protective device will not operate when required. |
| Corrective maintenance tasks | For tasks arising from condition based inspection: the PF Interval – the amount of warning that you get that the item is about to fail. For tasks arising from failure finding tasks / functional tests: the level of risk that the organisation is prepared to tolerate that the protective device will not operate when required. |
Let’s examine each of the task categories in turn, and discuss:
- What you should do to challenge or verify the frequency of that task, and
- If the task really is a critical task that determines the maximum interval between shutdowns, the options that may be available for extending that interval.
Fixed interval replacements or overhauls
Challenging/verifying task frequency
The frequency of Fixed Interval Replacements or Overhauls is determined by the useful “life” of the equipment item or component. The concept of a “Useful Life” only makes sense when an item has a rapidly increasing probability of failure once it gets past this life, as illustrated in Figure 1 below:
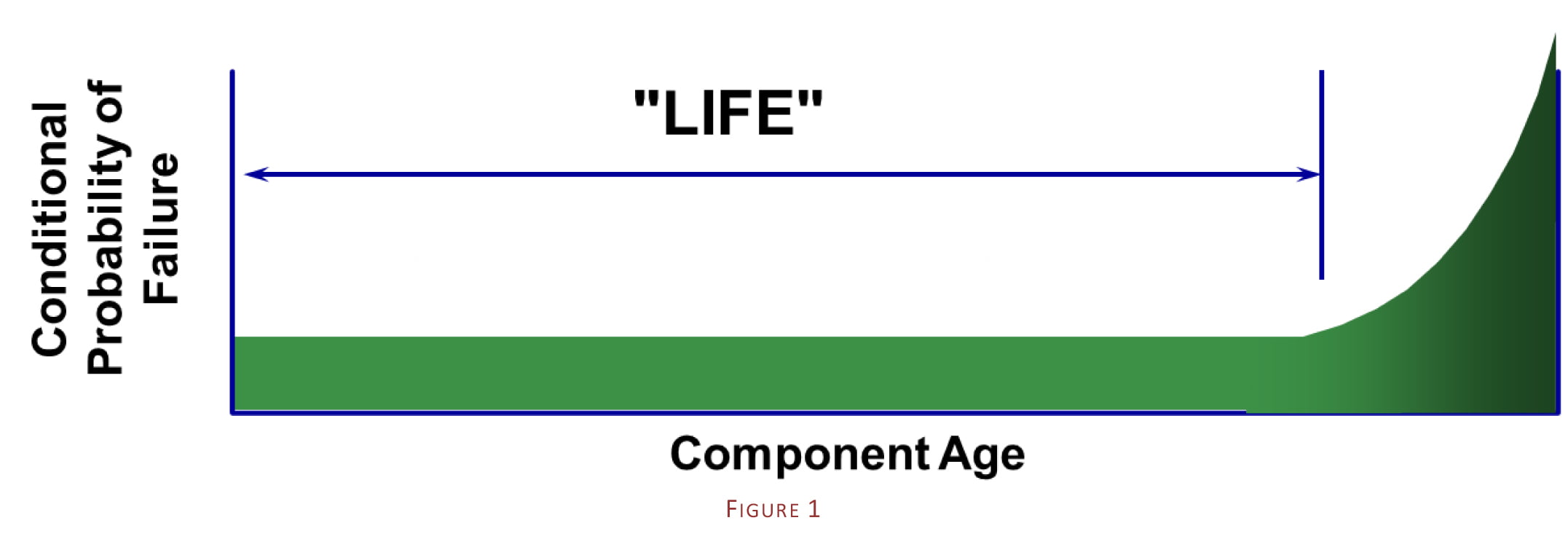
In practice, there are a few challenges associated with determining the “useful life” of an item.
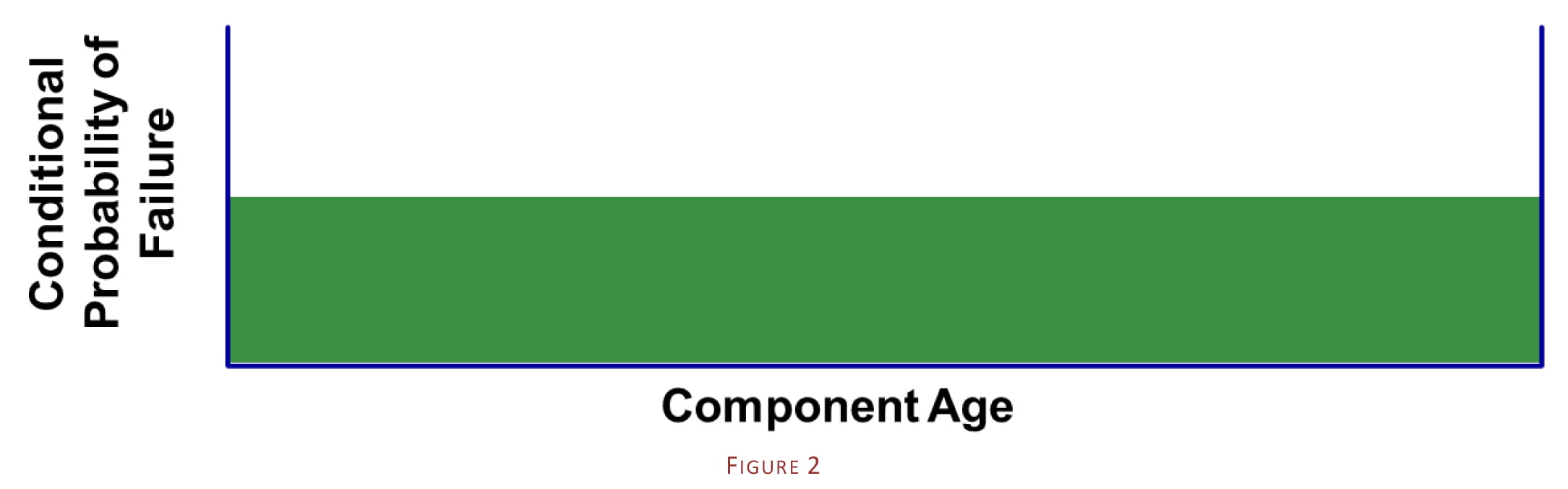
The first is to determine whether it, in fact, displays a failure pattern of a similar shape to that shown above. Often, it is assumed that most items “wear out”, but the reality is that they often fail for other reasons well before they get to the wear-out stage of their lifecycle. For example, research has shown that most rolling element bearings do not “wear out” – they instead display a random pattern of failure similar to that shown in Figure 2 below, where there is no relationship at all between the age of the bearing and its probability of failure. This is often because other factors intervene – such as quality issues regarding bearing fitment, lubrication quality and frequency, the existence of peak or impact loads on the bearing etc. etc.
Similarly, some equipment (including some centrifugal pumps) can demonstrate failure patterns similar to the one illustrated in Figure 3 below – with the probability of failure greatest in early life, rather than later life. In this case, replacing or overhauling the pump at a fixed frequency actually increases the probability of failure rather than decreasing it.

Be very wary of Original Equipment Manufacturers’ (OEM) recommendations regarding the frequency of fixed interval replacements. In making their judgements, they have to make assumptions regarding the operating conditions that may not apply at your site. By necessity they will be very conservative in their estimates of expected “useful life”, and there is also a significant conflict of interest when they make money from selling you the parts they are asking you to replace regularly. In our experience, component lives up to three times longer than the OEM recommendation can sometimes be achieved, and 50% increases in component lives above those recommended by the OEM are commonplace.
Even if you are sure that the item complies with the failure pattern shown in Figure 1 above, the next challenge is to determine at what point the probability of failure starts to rapidly kick up. Here, “Resnikoff’s conundrum” applies. The problem is this: we need failure data to be able to determine the point at which the probability of failure starts to increase; but if our existing preventive maintenance program is working as intended, it should be preventing failures, and therefore prevents us from collecting the data we need in order to determine the “useful life” of the item. Put simply, if we are preventing all failures, we don’t really know how far it may be possible to extend
the changeout/overhaul interval before we start to experience those failures. Further, in some cases, there may not be a rapid increase in the probability of failure, but instead a more gentle increase, and this makes the problem even more complex.
So, apart from just pushing out the replacement interval until we start having failures (which could be disastrous if the consequences of those failures are catastrophic), what can we do?
The answer is to initiate an “age exploration program”. This would consist of performing one or more of the following activities in order to determine the true “useful life” of the item:
- Performing regular inspections in order to assess the condition of the item and estimate the life remaining before the risk of failure becomes intolerable. This could be done either with the item remaining in situ (during a shutdown), using some form of online inspection technique (e.g. ultrasonic thickness testing), or by inspecting the item after it has been removed for replacement or overhaul, but before any repairs have been performed.
- Setting up specific online condition monitoring equipment specifically for the purpose of determining item condition and therefore item life (e.g. real-time vibration analysis)
- Performing accelerated life- testing of the item on a test bench and then interpreting those results in the context of real-life application of the item.
Options for extending the task interval
If a Fixed Interval task is the limiting factor preventing shutdown interval extension, then in some cases, it may be possible to permanently replace the fixed-life replacement or overhaul strategy with an on-condition repair/replacement strategy. This will be most likely when the cost of doing the condition based inspection is comparatively cheap, if the inspection can be done with the equipment still online and operating, and where the “useful life” of the item varies significantly depending on operating conditions. This can often be a useful method for testing whether component life can be extended, as it allows you to extend the interval between shutdowns while reducing the risks associated with unexpected premature failure
Other options that may be available include:
- Modifying the equipment in some way (e.g. by installing “longer life” components or using different materials) so that the critical component will last longer. Care must be taken to ensure that this doesn’t adversely affect operational efficiencies while operating, however.
- Operating the equipment in a different manner so that the critical component is not exposed to the same stresses (again, only if this does not have a significant adverse impact on operating efficiencies).
Condition based inspections
Challenging/verifying task frequency
As mentioned earlier, the frequency of Condition Based Inspections is determined by the amount of warning that you get that the failure is about to occur (the PF Interval). Inspections must be performed a frequency that is less than this PF Interval (and sufficiently less than the PF Interval so that you can avoid the consequences of an in-service failure of the item). In practice, determining the PF Interval is generally more easily done than determining the useful life of a component. The
people operating and maintaining the equipment generally have a pretty good idea of the warning signs associated with impending equipment failure, and how much warning is given. However, for critical equipment it is worth challenging this, in case invalid assumptions have been made. If knowing the PF Interval accurately is particularly critical, then it may be possible to initiate a “PF Interval exploration” program, similar to the “Age Exploration program” mentioned earlier. In this case, carefully controlled trials are conducted to deliberately run the equipment to failure (or very close to failure) and assess the amount of warning that is, in fact, obtained.
Options for extending the task interval
If a Condition Based Inspection task is the limiting factor preventing shutdown interval extension then the following options may be available:
- Using a different Condition Monitoring technique with a longer PF Interval. For example, using vibration analysis will give more warning than listening to a bearing for audible noise. This is one of the advantages of using the Internet of Things and Big Data for failure prediction – by using and correlating data from a range of different sources it is often possible to get earlier warning of impending failures
- Replace the Condition Based Inspection task with a Fixed Interval Replacement task. In some cases, if the failure mode displays a wearout failure pattern similar to that shown in Figure 1, then it may be more effective to simply replace the item on a fixed interval basis. If, for example, you are finding that you consistently need to replace the item every third inspection, then why not just replace it automatically at three times the current inspection interval?
Failure finding tasks/functional tests
Challenging/verifying task frequency
Failure finding tasks are used to detect whether an item has already failed. This is different to a Condition Based Inspection where the task is used to detect whether an item is about to fail. So Failure Finding tasks only apply to Hidden Failures (in Reliability Centered Maintenance terminology) – typically protective systems and devices such as alarms, interlocks, trips etc.
If the interval between tests is extended, then this increases the risk that the protective device or system will not operate when it is required. Significant equipment damage, an environmental incident or a serious safety incident may result. The question to be answered, therefore, is whether this additional risk is able to be tolerated by your organisation. It is beyond the scope of this article to go into the mathematics behind the calculation of that risk, but if adequate data is available, the risk can be quantified. In some cases, the frequency of inspection/testing may be mandated by regulatory authorities, and it then becomes a question of whether the organisation is willing to negotiate an exemption from this requirement. We recommend, however, that attention be focused on those protective devices and systems that are the most important in terms of the consequences of failure if they do not operate. These are the systems for which you will need to more accurately obtain data, and assess the risk.
Options for extending the task interval
If a Failure Finding task or Functional test is the limiting factor preventing shutdown interval extension then the following options may be available:
- Improve the reliability of the protective device or system. The more reliable it is, then the less often it will need to be tested.
- Improve the reliability of the underlying equipment/process that the protective device is protecting. The less often you require the protective device or system to operate, then the less often it will need to be tested.
- Consider installing additional, redundant protection. This can significantly increase the interval required between tests. For example, installing two independent pressure relief valves on a vessel significantly increases the testing interval in order to obtain the same level of overall risk – assuming that only one pressure relief valve is required to operate in order to provide the protection.
Corrective maintenance tasks
Because corrective maintenance tasks have arisen as a result of Condition Based Inspections (either routine Condition Based Inspections initiated by the formal Preventive Maintenance program, or ad hoc inspections performed by operators and others), the same principles apply to these tasks as apply to Condition Based Inspections. The risk associated with extending shutdown interval for these tasks is that the equipment may fail prior to the next planned shutdown.
Can the new shutdown strategy be practically implemented?
Once you have completed the preceding analysis, the next step is to consider whether your new shutdown strategy can be practically implemented. There are a number of considerations here.
- How big is each shutdown going to be? Typically, you will find that if you extend the interval between shutdowns there will be some tasks that used to be performed every second (or more) shutdown that will now need to be completed every shutdown. For example, if you change the shutdown interval from 12 weeks to 16 weeks, there may be some tasks that used to be done every 24 weeks that will now need to be performed every 16 weeks (not 24 weeks). This may mean that the amount of resources required for each shutdown will be greater. This may have an adverse impact on:
- The capability of your preferred contractor to adequately resource a shutdown of this size
- The amount of onsite accommodation required (and camp accommodation if in a remote area) – will you have sufficient capacity to house additional contractors?
- The logistics of transporting contractors to site. If in a remote area, can enough flights/buses etc be mobilised to get people to site in a timely manner?
- The amount of support equipment required, such as cranes, hire equipment etc.
- The amount of resources required to adequately plan, schedule and manage these larger shutdowns
- Conflicts between activities to be performed at the same time – for example welding to be performed in an area above another maintenance activity.
All of these issues may be able to be overcome, but may require additional expenditure – which may make the change of shutdown strategy less attractive.
- How will your new shutdown strategy integrate with the rest of your business? If you are working on one site of a multi-site integrated business (e.g. a mining company with integrated mine, process plant, rail and port facilities, or a chemical plant that feeds other continuous process plants downstream) then you may find that your new shutdown strategy does not easily align with theirs. This can then mean that even though there are uptime benefits for your plant, there are no uptime benefits for the entire process/supply chain, because when you are up, related plants are unable to provide feed or take away product, and when you are down, they required feed from your plant. Total supply chain modelling may be required in order to determine the true benefits to the whole business of your changed strategy.
- How will the proposed downtime periods align with other external influences? Ideally you want to be able to steer clear of having shutdowns occur during times of peak customer demand (if you are a seasonal business). You also would like shutdowns not to occur during traditional holiday times (such as Christmas, Easter, Ramadan etc)
It is important to understand all of these implications before making the decision to change your shutdown frequency.
Conclusion
I hope that this article has helped you to understand some of the key items to consider before adjusting your shutdown frequency. Careful forethought and some critical analysis can help to avoid the more significant risks associated with making this change, and ensure that the full benefits of extending shutdown frequencies can be realised. We can, if desired, assist you to perform that analysis and help you to implement the changes necessary to realise those benefits. Contact us now to discuss your needs, and how we can help.
For future useful articles sign up to our mailing list.