
In a previous article, we discussed the key elements of the Reliability Centered Maintenance (RCM) process. In this article we give a brief summary of the key elements of its close relation, Preventive Maintenance Optimisation (PMO).
Preventive maintenance optimisation standards
Unlike the situation that exists with Reliability Centered Maintenance, there are no internationally recognised standards for performing Preventive Maintenance Optimisation. A quick literature search using the term Preventive Maintenance Optimisation reveals that there are a number of scholarly articles on the topic, and a wide range of approaches taken by different vendors and consultants in the field.
These approaches can be divided into two camps:
- Quantitative or Stochastic Approaches – which typically use statistics, hazard functions, Weibull Analysis, Monte Carlo analysis and/or Markov models to simulate failure probabilities and consequences over time, and
- Qualitative (or semi-quantitative) Approaches – which often apply key Reliability Centered Maintenance concepts and approaches, but which seek to arrive at the results more quickly than would be the case if using a full RCM approach.
In this article we will focus on the second of these two camps. Our only comments regarding quantitative approaches is to note that these can only be effective if there is reasonable data – and in particular, reasonable data regarding equipment failures or impending failures. While this may be possible where large fleets of essentially identical equipment operate under essentially identical operating conditions, the situations where this is true is comparatively few and far between. Large fleets of mobile equipment (such as trucks, or railway rolling stock) may be possible candidates for this type of analysis, but once again, depend heavily on the existence of complete and reliable data.
Assetivity’s preferred approach to preventive maintenance optimisation is to conduct a type of “reverse RCM”, and it is this approach that we will outline in this article.
This approach consists of asking the following seven questions regarding the asset or system under review:
- Current PM tasks – what are the current PM tasks being performed?
- Failure Modes – what failure modes are these addressing?
- In-service Failures – what in-service failures are currently being experienced, and what are their causes?
- Hidden Failures – what protective devices and systems are in place and what are the potential failure modes associated with these?
- Failure Consequences – in what way does each failure matter?
- Proactive Tasks – what can be done to predict or prevent each failure?
- Default Actions – what should be done if a suitable proactive task cannot be found?
Each of these questions is discussed briefly below.
Current preventive maintenance tasks
One of the key concepts of Reliability Centered Maintenance is that all preventive maintenance tasks should be directed at preventing specific failure modes (or causes of failure). In preventive maintenance optimisation, as the primary objective is to review and optimise the current Preventive Maintenance program, the starting point is to begin by assembling all of the tasks that this Preventive Maintenance program consists of. Note that it will be essential to be quite specific regarding the tasks being undertaken. For example, a Preventive Maintenance task described as “500-hour service” would need to be broken down into the various tasks that the 500-hour service consists of. This needs to be done so that (in the next step) the Failure Mode (or Modes) that each task is addressing can be identified and critically reviewed.
Note that these tasks (and the detail contained within them) may exist in a number of disparate systems. Ideally, they would all be contained within your CMMS or EAM system, but often they are not. For example, the CMMS may contain a PM activity titled “Perform Monthly Vibration Analysis”, but the details of what equipment is analysed, and what it is analysed for may be contained in a separate Condition Monitoring System. It is also important to include routine maintenance or equipment inspection activities performed by plant operators in this analysis, and the details of these are usually not contained within your CMMS or EAM system.
Failure modes
Once each current PM tasks has been identified, the next step in the preventive maintenance optimisation process is to identify the Failure Modes which these tasks are intended to address. In this context, note that we consider a “Failure Mode” to be a cause of Failure. In performing this analysis it is important to limit the analysis to failure modes which are “reasonably likely” to occur on the same or similar equipment operating in the same context. This requires elements of experience and engineering judgement. It is also important to ensure that causes are described in enough detail to ensure that time and effort are not wasted trying to treat symptoms instead of causes.
In-service failures
In this step, we need to add to the list of failure modes under consideration those that have not been prevented as a result of the Preventive Maintenance routines that have been put in place. This requires us to obtain details of the Failure History for the equipment or system being analysed. More specifically, it also requires us to be able to identify the causes of those failures. The starting point for this is to obtain from your CMMS or EAM details of the Breakdown and/or Unplanned Work Orders that have been raised against the equipment. However, we should also recognise that, in the real world, in most industries, this Work Order history is likely to be incomplete, possibly inaccurate, and is also unlikely to accurately record the cause of equipment failure (at least to the level of detail that we require when reviewing the PM program). It is highly likely, at this point, that you will need to supplement the data contained in your corporate information systems with the knowledge held in the heads of those that operate and maintain the plant. Another potentially useful source of information regarding equipment failures is your organisation’s Downtime or Loss Accounting log, if it has one. However, once again, it is highly advisable to combine this with the knowledge and experience of your plant operators and maintainers in order to ensure that you get a complete and accurate picture of what failures are occurring on the equipment.
For each failure, you should identify the Failure Mode (or cause) and add it to the list generated in Step 2 of this process.
Hidden failures
There is one final class of failure modes that you should consider in your preventive maintenance optimisation analysis. These are failure modes that may not be being prevented through existing PM (so won’t appears in the list of failure modes generated in Step 2), and may have actually happened, but won’t appear in your failure history (and so won’t be added in Step 3). They are Hidden Failure modes. In RCM terminology, a Hidden Failure is one which, when it happens on its own, will not become apparent under normal circumstances (unless a PM task is in place to detect it). An example of this is failure of a smoke detector. If no PM task was in place to periodically test the smoke detector, then its failure (so that it could not detect a fire even if one were to occur) would not become apparent until a fire occurred (and the consequences of this could, potentially, be disastrous). Hidden Failures are most often associated with Protective Devices and Systems which are not fail-safe. This could include alarms, interlocks, trips, stand-by equipment and many other devices and systems.
To ensure that we consider Hidden Failures in our preventive maintenance optimisation analysis, we strongly recommend that time be taken to specifically seek out protective devices and systems on the equipment being analysed, and identify failure modes that are associated with these systems that are Hidden. These failure modes should be added to the list of Failure Modes generated in Steps 2 and 3.
So far in this process, we have spent time identifying the Failure Modes for which the Preventive Maintenance program needs to be optimised. It has been, up to this point, largely a data collection exercise. In the following steps, we now start to analyse this data and make decisions regarding the most appropriate PM tasks to put in place to address each Failure Mode.
The observant amongst you will recognise that the following three steps are essentially identical to the final three steps in the RCM process. If you have read our previous article “What is RCM?” then you will find that we repeat ourselves here, but if you have not, here is this information again!
Failure consequences
Another key concept underpinning Reliability Centered Maintenance is that the primary objective of a Preventive Maintenance program is not necessarily to avoid or minimise failures themselves, but to avoid or minimise the consequences of those failures. There is little point in spending a lot of time and money preventing failures that have little or no consequences associated with them. On the other hand, if a failure has serious consequences, we may be able to justify going to great lengths to avoid those consequences. In this way, the RCM process focuses attention on the maintenance activities which have most effect on the performance of the organization, and diverts energy away from those which have little or no effect.
This fifth step in the RCM process classifies the consequences associated with each failure mode as belonging to one of the following four groups:
- Hidden failure consequences: Hidden failures have no direct impact, but they expose the organization to multiple failures with serious, often catastrophic, consequences. (Most of these failures are associated with protective devices which are not fail-safe.)
- Safety and environmental consequences: A failure has safety consequences if it could hurt or kill someone. It has environmental consequences if it could lead to a breach of any corporate, regional, national or international environmental standard.
- Operational consequences: A failure has operational consequences if it affects production (output, product quality, customer service or operating costs in addition to the direct cost of repair)
- Non-operational consequences: Evident failures which fall into this category affect neither safety nor production, so they involve only the direct cost of repair.
In making these decisions, we need to consider what the potential effects would be for each failure mode. This involves considering:
- what evidence is there (if any) that the failure has occurred
- in what ways (if any) does the failure mode poses a threat to safety or the environment
- in what ways (if any) does the failure mode affects production or operations
- what physical damage (if any) is caused by the failure
- what must be done to repair the failure.
The consequence evaluation process shifts emphasis away from the idea that all failures are bad and must be prevented. In so doing, it focuses attention on the maintenance activities which have most effect on the performance of the organization, and diverts energy away from those which have little or no effect.
Proactive tasks
In preventive maintenance optimisation (and reliability centered maintenance), failure management techniques are divided into two categories:
- Proactive Tasks: these are tasks undertaken before a failure occurs, in order to prevent the item from getting into a failed state. They embrace what is traditionally known as ‘predictive’ and ‘preventive’ maintenance, although we will see later that RCM uses the terms Scheduled Restoration, Scheduled Discard, and Condition-based Maintenance
- Default Actions: these deal with the failed state, and are chosen when it is not possible to identify an effective proactive task. Default actions include failure-finding, redesign and run-to-failure.
Many people still believe that the best way to improve equipment reliability is to do some kind of proactive maintenance on a routine basis. Conventional wisdom suggested that this should consist of overhauls or component replacements at fixed intervals. Figure 1 illustrates the fixed interval view of failure.

Figure 1 is based on the assumption that most items operate reliably for a period of time, and then wear out. Classical thinking suggests that extensive records about failure will enable us to determine this life and so make plans to take preventive action shortly before the item is due to fail in future.
This model is true for certain types of simple equipment, and for some complex items with dominant failure modes. In particular, wear-out characteristics are often found where equipment comes into direct contact with the product. Age-related failures are also often associated with fatigue, corrosion, abrasion and evaporation.
However, equipment in general is far more complex than it used to be. This has led to significant changes in the patterns of failure, as shown in Figure 2. The graphs show conditional probability of failure against operating age for a variety of electrical and mechanical items.
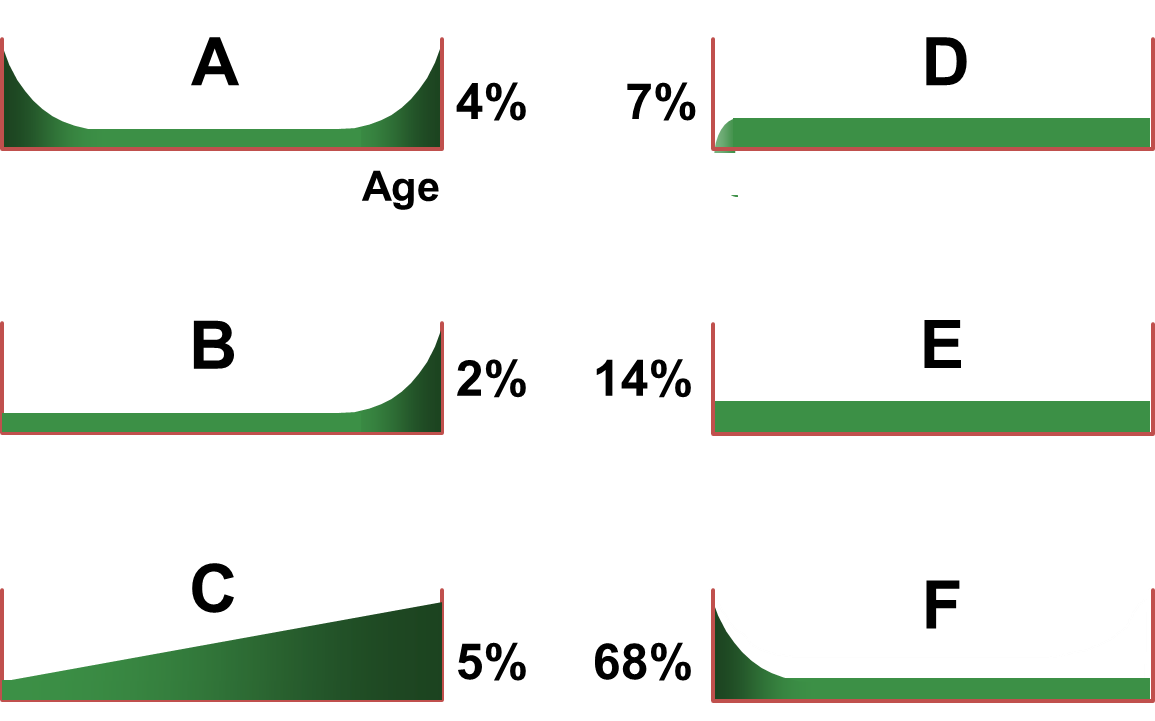
Pattern A is the well-known bathtub curve. It begins with a high incidence of failure (known as infant mortality) followed by a constant or gradually increasing conditional probability of failure, then by a wear-out zone. Pattern B shows constant or slowly increasing conditional probability of failure, ending in a wear-out zone (the same as Figure 1).
Pattern C shows slowly increasing conditional probability of failure, but there is no identifiable wear-out age. Pattern D shows low conditional probability of failure when the item is new or has just been refurbished, then a rapid increase to a constant level, while pattern E shows a constant conditional probability of failure at all ages (random failure). Pattern F starts with high infant mortality, which drops eventually to a constant or very slowly increasing conditional probability of failure.
Studies done by Nowlan and Heap in the 1960s on civil aircraft showed that 4% of the items conformed to pattern A, 2% to B, 5% to C, 7% to D, 14% to E and no fewer than 68% to pattern F. (The number of times these patterns occur in aircraft is not necessarily the same as in other industries. But there is no doubt that as assets become more complex, we see more and more of patterns E and F.)
These findings contradict the belief that there is always a connection between reliability and operating age. This belief led to the idea that the more often an item is overhauled, the less likely it is to fail. Nowadays, this is seldom true. Unless there is a dominant age-related failure mode, age limits do little or nothing to improve the reliability of complex items. In fact, scheduled overhauls can actually increase overall failure rates by introducing infant mortality into otherwise stable systems.
As mentioned earlier, preventive maintenance optimisation and reliability centered maintenance divide proactive tasks into three categories, as follows:
- Scheduled Restoration tasks
- Scheduled Discard tasks
- Condition-based Maintenance tasks.
- Scheduled Restoration and Scheduled Discard tasks
Scheduled restoration entails remanufacturing a component or overhauling an assembly at or before a specified age limit, regardless of its condition at the time. Similarly, scheduled discard entails discarding an item at or before a specified life limit, regardless of its condition at the time.
Collectively, these two types of tasks are now generally known as Preventive Maintenance. They used to be by far the most widely used form of proactive maintenance. However, for the reasons discussed above, they are much less widely used than they used to be.
The continuing need to prevent certain types of failure, and the growing inability of classical techniques to do so, are behind the growth of Condition-based approaches to failure management. The majority of these techniques rely on the fact that most failures give some warning of the fact that they are about to occur. These warnings are known as Potential Failures, and are defined as identifiable physical conditions which indicate that a Functional Failure is about to occur or is in the process of occurring.
The new techniques are used to detect potential failures so that action can be taken to avoid the consequences which could occur if they degenerate into Functional Failures. They are called Condition-based tasks because items are left in service on the condition that they continue to meet desired performance standards. Condition-based tasks can include the use of sophisticated technology, such as Vibration Analysis, Thermography, Oil Analysis, Ultrasonics and others, but they can also include simple techniques such as visual inspection. Used appropriately, on-condition tasks are a very good way of managing failures, but they can also, if not applied in the right way and at the right frequency, be an expensive waste of time.
In preventive maintenance optimisation, we use the same structured decision-making process that is used in RCM. This has clear evaluation criteria and enables decisions regarding the selection of the appropriate Proactive Task to be made with confidence.
Default actions
Preventive maintenance optimisation and reliability centered maintenance recognizes three major categories of default actions, as follows:
- Failure-Finding: Failure-finding tasks entail checking hidden functions periodically to determine whether they have failed (whereas condition-based tasks entail checking if something is failing).
- Redesign: redesign entails making any one-off change to the built-in capability of a system. This includes modifications to the hardware and also covers once-off changes to procedures.
- No Scheduled Maintenance: as the name implies, this default entails making no effort to anticipate or prevent failure modes to which it is applied, and so those failures are simply allowed to occur and then repaired. This default is also called run-to-failure.
Conclusion
I hope that this has given you a flavour of what preventive maintenance optimisation is all about. If you are interested in learning more, then why not consider attending one of our two-day courses in reliability centered maintenance and preventive maintenance optimisation?
Training and implementing PM Optimisation in for 15 years.
There is a lot more to successfully applying this process than we have had time to cover in this article. Our RCM & PMO cause runs in various locations around Australia, or we can deliver the course in-house for your organisation. Our consultants can also facilitate preventive maintenance optimisation studies and help you to embed the PMO process within your organisation. Contact us if you would like to discuss how we may be able to help you.
-
 RCM & PMO for Team MembersOriginal price was: $2,150.00.$1,935.00Current price is: $1,935.00.
RCM & PMO for Team MembersOriginal price was: $2,150.00.$1,935.00Current price is: $1,935.00. -
Introduction to Reliability ImprovementOriginal price was: $1,075.00.$967.50Current price is: $967.50.

